
当前位置:首页 > 技术视窗 > IPFS技术 > IPFS底层技术详解:分布式哈希表DHT(1)
IPFS底层技术详解:分布式哈希表DHT(1)
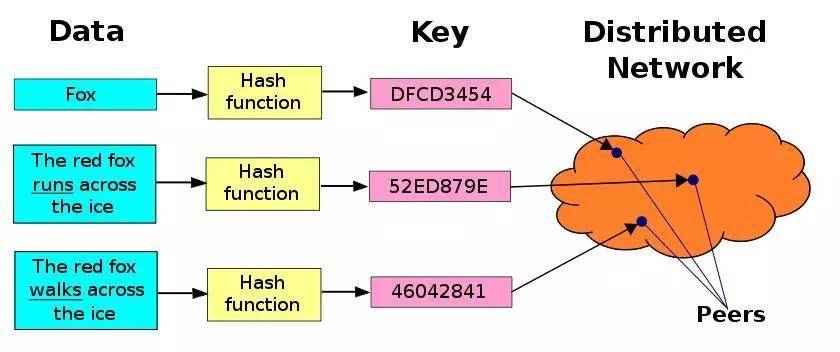
DHT(Distributed Hash Table)即分布式哈希表,是实现分布式存储和下载的关键技术,现已广泛应用在P2P网络中,例如迅雷的BitTorrent下载技术。

分布式网络
想要了解分布式哈希表的技术实现,我们先来看看什么是哈希:
哈希算法(Hash,也称为散列算法)可谓密码学史上最伟大的发明之一,哈希算法的产生成功地让密码破解的难度大大提高,让互联网的发展可以放开手脚。
哈希算法简单来说就是一个函数,函数相比大家在中学时候都学过:y=f(x)。这里,x就是原本的信息的摘要,我们称之为键(key);而y就是经过加密之后的信息的代号,也就是哈希值。这个函数有一些特殊的性质:
(1)无论x有多复杂,根据其某些特征生成的y都是固定长度的。例如我们固定y的长度是128Bit,即计算机里的128位,则无论x是“1”还是“富强、民主、文明、和谐、自由、平等、公正、法治、爱国、敬业、诚信、友善”,y的长度永远是128位。
(2)当x发生微小的变化时,y值都会与之前完全不同。我们来拿SHA1(一种哈希算法)来举例:当x值为“123456789”时,其哈希值为“F7C3BC1D808E04732ADF679965CCC34CA7AE3441”;当x值为“123456789.”,即在9之后加了一个点时,哈希值就变成了“ED005B69BC65E50B86EFBFA2EEE5A9A9522C4A79”。我们可以看到,几乎是每一位都不相同,在这里我们不去探讨函数的设计,但大家看到这样的结果想必就知道我想说什么:原信息哪怕只有微小的改变,都会导致其哈希值,也就是y的天差地别。
(3)无法通过哈希值倒推原信息。这就是函数知识中所提到的,不可逆函数。怎样的函数是可逆的呢?就是当x和y值是一一对应的,也就是一个x对应一个y(函数基本性质),而每一个y也只对应一个x。然而哈希函数中,同样的y值可能会由很多的x值生成,也就是说,每一个哈希值并不仅仅只对应一个value。上文所提到的key仅仅是原文的摘要。这个摘要你可以理解为原文的特征值,1T的数据经过哈希加密所得到的哈希值长度依然一样,当然不可能用有限的位数去加密多达1T的数据,只能挑选数据中的一部分,这一部分数据可以说是可以充分代表这份数据唯一性的部分,作为key。这也可以说明了哈希运算的不可逆性。
或许你会问,这不还是有机会破解吗?
不错,确实存在理论上破解的可能。但我们要明确一些前提条件:比特币网络里,每个区块的哈希是利用了SHA256算法,有64位哈希值,也就是说理论上总共存在2的256次方个哈希(这里我给小白解释一下,为什么是2的256次方。计算机里的信息都是2进制的,也就是每一位都是0或者1,哈希中所含的数字和字母都是16进制的,16的64次方也就是2的256次方,也就是说哈希码中的每一个字符都是由4位二进制数组成。)。而哈希算法的特征就是其是根据x的某些特征进行计算,而符合这个特征的x有无数多种,所以不可能轻易寻找到真正的原有信息,因为当n趋向无穷大时,1/n=0。
很多不可能其实是概率趋向于0的情况,逻辑上依然存在可能
哈希算法在加密上有了很广泛的应用。举个例子,你的银行卡密码不是直接存储在银行系统里,系统里只会存储你密码对应的哈希,每次验证时候都只会验证哈希是否相同。这样就算银行系统被黑,黑客也无法得知你的银行卡密码。
说到这里,想必大家都对哈希算法有了简单的了解了。为了保证篇幅不会太长,今天我先说一部分DHT的内容。
首先,我想说的是,DHT只是一个概念,有很多种实现方式。我们先来看看什么是哈希表:
哈希表,又称为散列表,这个表是用来存放键值对的。什么是键值对呢?不像银行卡密码那样只需要存储哈希,当给文件加密时,不仅仅需要存储文件的哈希,也需要存储文件本身。这样就需要将文件和哈希成对存储以方便查找。我们再来举个例子:
对于普通的哈希表而言,扩容的代价是很大的。因为普通的Hash计算地址方式如下:Hash(Key)%M(%为取余运算,也就是Hash(Key)整除M之后的余数),为了演示方便,举个极端的例子如下:
假设哈希函数为 hash(x)=x ,哈希表的长度为5(有5个桶,桶就是存储哈希表的空间)
key=6时,hash(6)%5 = 1,即Key为6的元素存储在第一个桶中
key=7时,hash(7)%5 = 2,即Key为7的元素存储在第二个桶中
Key=13时,hash(13)%5=3,即Key为13的元素存储在第三个桶中….
这就是普通的哈希表,然而这样的哈希表有很大的问题,我们继续看:
假设现在hash表长度扩容成8,那么Key为6,7,13 的数据全都需要重新哈希。因为,
key=6时,hash(6)%8 = 6,即Key为6的元素存储在第六个桶中
key=7时,hash(7)%8 = 7,即Key为7的元素存储在第七个桶中
Key=13时,hash(13)%8=5,即key为13的元素存储在第五个桶中….
从上可以看出:扩容之后,元素的位置全变了。比如:Key为6的元素原来存储在第一个桶中,扩容之后需要存储到第六个桶中。
因此,这是普通哈希的一个不足:扩容可能会影响到所有元素的移动。这也是为什么:为了减少扩容时元素的移动,总是将哈希表扩容成原来大小的两倍的原因(有数学证明,扩容成两倍大小,使得再哈希的元素个数最少)。
当桶的数量较大时,调整的程度会更加夸张
所以哈希表的本质,就是当你寻找某个信息时,最终都是一个将哈希值取余去寻找桶的一个过程,但我们也看到了,当有新的节点加入或者旧节点退出时,都需要重新存放键值对,当信息量较大的时候就容易导致网络阻塞。
那么有没有方法可以解决这个问题呢?
聪明的人类发明了一致性哈希,真正让分布式哈希表得以高效地实现。至于什么是一致性哈希,以及分布式哈希表的寻址方式,我们下次来说。
-
IPFS底层技术详解:分布式哈希表DHT(1)
作者:分布式哈希表2020-11-06 14:51:43
-

激励措施在BitTorrent中建立稳健性
作者:filecoin技术2020-11-06 14:53:36
-

哈希是什么?它和IPFS什么关系?
作者:哈希函数2020-11-06 15:00:19
-

简单解释下:Filecoin到底是挖什么矿?
作者:IPFS挖矿2020-11-06 14:55:45
-

干货 | 未来已来,IPFS究竟能带来些什么?
作者:IPFS技术2020-11-06 14:54:01


-
- 2020-11-06
-
- 2020-11-06
-
- 2020-11-06
-
- 2020-11-06
-
- 2020-11-06
-

- 2020-11-24
